BORA Scraper Downloader
Automated extraction of 14,742 legal PDFs from Argentina's Official Gazette.
Pipeline Output
Automated File Organization
Intelligent directory sorting by year, month, and section.
The Problem
Legal and compliance teams in Argentina need access to historical records from the BORA (Boletín Oficial). But the official website has no bulk download option, blocks automated requests, and requires specific session handling to access PDFs. Manually downloading years of documents is not viable.
Technical Challenges
Session Priming
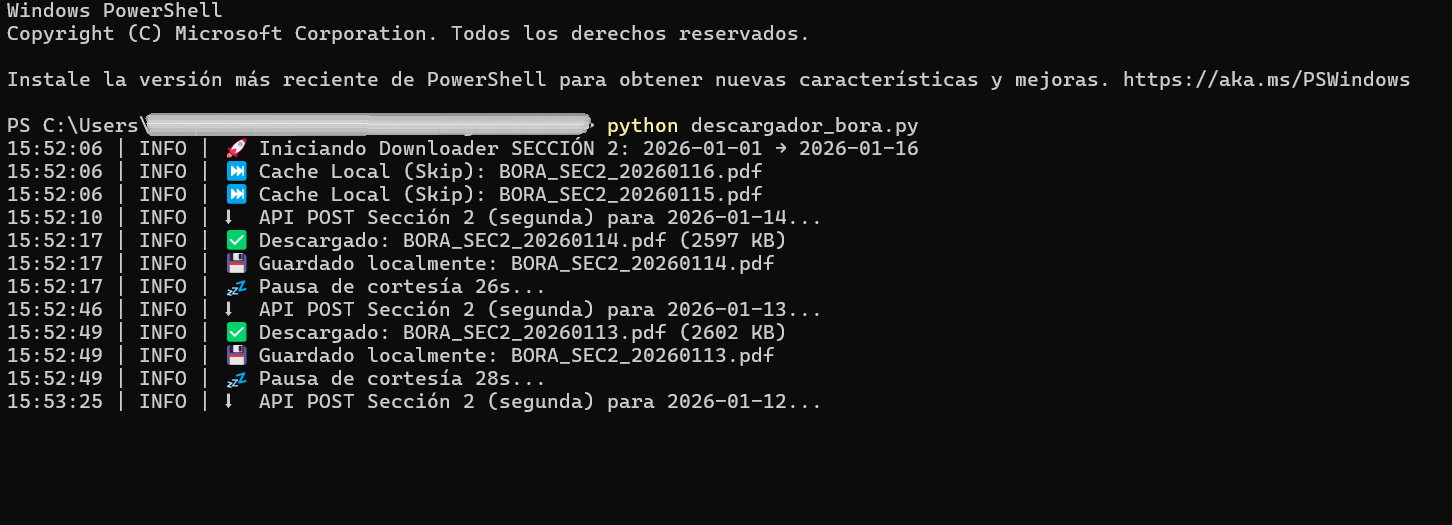
The server rejects direct PDF requests. You must first visit the page (GET), receive cookies, then POST to the download endpoint with exact parameters.
Anti-Bot Detection
Repeated requests trigger IP blocks. The server fingerprints User-Agent strings and request patterns.
Data Integrity
Some downloads fail silently, producing corrupted files (<1KB).
My Solution
Request flow per document
- Replicate exact browser flow: GET page → set cookies → POST download
- Rotate through 10+ modern User-Agents per session
- Random delays between requests (10-30 seconds) to mimic human behavior
- Destroy and recreate HTTP session every 5 days to avoid cookie accumulation
- Verify file size post-download, flag corrupted files for retry